 아 맞다, 그거
아 맞다, 그거
1. 서론
최초에 Trinity Parser를 만든게 24년 7월이었던 것 같다.
Java + Spring / React 를 이용해서 웹 앱을 제작했고, UI/UX 디자이너가 없어서 Figma에서 없는 디자인 솜씨로 최대한 노력했다.
당근 마켓을 레퍼런스 삼아 대충 만들었는데, 만들고 보니 처참했다...
처음에는 내 NAS에서 배포를 하다가 내 IP가 공격받을 것 같아서 Cloud를 쓰는 것으로 변경했다.
AWS EC2는 과금된 기억이 있어 쉽사리 손이 가지 않았는데
그 당시 Oracle에서 프리티어가 파격적이어서 Oracle cloud를 사용하고 있다.
ARM 아키텍처 인스턴스는 엄청난 메모리와 코어 수를 자랑한다.
그렇게 2년 정도 100% 가용성으로 쉼없이 서비스되었다. 정말 잘 버텼다고 생각한다.
물론, 내 웹 앱은 특정 시기에만 사용자가 생기기 때문에 스트레스가 높지는 않다.
1.0.0:
2.0.0:

2.1.0:

실제로는 1.2.0일 것 같은데 내 멋대로 버전 정보를 세팅했다..
그리고 26년,,, 2.2.0이 배포가 되었다.

2. 업데이트의 동기??
여기에는 두 가지 이유가 있다.
첫째, UI/UX가 너무 안좋았다.
최근 실무를 하면서 FE (Frontend)를 하다보니 어떤 것에 조금 신경을 써야 하는지를 알게되었다.
또, AI가 발전하면서 UI/UX에 대한 고민을 나눌 수 있는 존재가 생겼고, 이것이 업데이트를 진행할 수 있게 해주었다.
둘째, 기존 백엔드의 로직은 개인 정보를 다루는 데에서 위험이 존재했다.
이 내용을 풀기 위해서는 기존에 Trinity Parser의 구조를 가지고 설명할 필요가 있다. 여기에도 두 가지 정도의 내가 인지하고 있는 위협이 있다.
첫 번째 위협은 인지는 하고 있으나 해결할 수 없는 문제이다.

Trinity Parser는 로그인이나 정보를 한 번 중계해주는 역할이다.
그 과정에서 내가 제작한 BE (Backend)는 학교 시스템의 웹 서버랑 http 통신을 하게 된다.
당연히 https 프로토콜을 사용하고 있고, 나도 그걸 알고 있기 때문에 안에 평문을 실었다.
하지만 실제로는 조금 위험이 있긴 하다.
예를 들어, 웹 서버에서 패킷을 가로챌 수 있으면서 웹 서버의 비밀키를 알 수 있는 상태라면 패킷을 가로채서 내부 내용을 조회하는 것이 가능하다.
또 당연하게도 내 웹 서버가 해커에게 장악당했다면 https로 암호화 되기 직전의 payload를 엿보는 것이 가능할 것이다.
음,,, 근데 이걸 조치할 수는 없다.
왜냐하면 학교 웹 서버에 보내야 하는 데이터의 형식은 정해져 있기 때문이다.
내가 암호화를 해서 보내고 싶다고 해도 학교 웹 서버가 그대로인 이상 추가적으로 조치할 수가 없다.
두 번째 위협은 기존 백엔드의 설계 구조에서부터 비롯된다.

사용자는 BE로 로그인 요청을 보내고 BE는 사용자 대신 Web server에 실제로 로그인을 진행한다.
이 결과로 받은 Auth Token을 Redis에 담아두고, 클라이언트의 세션을 유지시키면서 두고두고 사용한다.
여기서 이해하기 쉽도록 Auth Token이라고 설명했지만, 실제로는 쿠키나 CSRF Token과 같은 여러 인증 정보가 존재한다.
이때, BE는 제 3자인데 다른 사용자의 인증 정보를 대신 가지고 있는 아주 위험천만한 구조가 탄생한다.
내 입장에서는 쉽게 사용하려고 보관했던 것인데 오히려 더 큰 문제를 야기할 수 있었다.
이 위협을 없애기 위해서 2.2.0 업데이트를 진행하게 되었다.
이때, 기존에 Java + Spring으로 이루어진 백엔드는 너무나도 무거웠기 때문에 조금 더 쉽게 구현할 수 있는
NestJS 기반의 백엔드로 마이그레이션을 진행했다.
심지어 NestJS는 MSA 구조를 직접적으로 지원하기 때문에 확장성 면에서도 더욱더 좋은 웹 앱이 될 수 있었다.
3. 2.2.0에서의 가장 큰 특징
아무래도 백엔드의 마이그레이션이 가장 큰 특징이라고 얘기할 수 있다.
첫째, 이전 단에서 얘기했던 것 처럼 인증 정보를 BE가 가지고 있는 것이 아니라 전부 클라이언트한테 넘겼다.
BE는 오로지 목적지로의 중계와 정보의 추가적인 가공만 담당한다.
둘째, MSA 구조 채택 그리고 탈 RestAPI 이다.
MSA 구조를 가지고 가면서 자연스럽게 메세지 브로커 기반의 비동기 통신을 사용하는 것으로 바꾸었다.
메세지 브로커로는 Kafka를 사용했다.
최근에 안 사실이지만 Kafka는 완전 비동기 통신으로 알고 있었는데, 토픽을 발행하고 Reply 토픽을 기다리는 식으로 동기 비슷하게 작동할 수 있다는 것을 배웠다.
이외에도 추가적인 기술적 발전이 있었다.
먼저, BE에서의 기술적 발전이다.
최근 대세 DB인 코끼리 DB!! Postgres를 사용하는 것으로 변경했다.
다음으로는 MSA를 위해서 API Gateway를 도입했다.
도커 컴포즈로 전부 컨트롤 되게 했고, 최근에 Jenkins를 적극적으로 사용하면서 Jenkins pipeline을 통해 CI/CD 자동화까지 적용했다.
이제는 Push만 누르면 배포가 완료되는 시대에 있다...!
다음으로는, FE에서의 기술적 발전이 있었다.
리액트 쿼리를 이용해서 쿼리 캐싱이나 쿼리 결과를 State로 다루는 것, 그리고 특정 상황에서 데이터 자동 갱신 등을 쉽게 관리할 수 있도록 했다. 특히 InfiniteQuery를 이용한 무한 스크롤은 혁신이라고 생각한다.
여기에 윈도잉 기법을 적용해 사용자에게 보여지는 부분만 렌더링되도록 하면 거의 끝판왕이라고 생각한다.
(실무에서 이걸 공부한 게 참 도움이 많이 되었다...)
마찬가지로 FE도 Jenkins pipeline을 통해 CI/CD 자동화가 적용되었다.
UI 역시 Shadcn과 같은 디자인 컴포넌트를 적극 활용했고, 덕분에 통일성 있는 UI를 쉽게 만들어낼 수 있었다.
전역 상태 관리를 위한 Zustand, CSS를 걷어내게 해준 Tailwind와 같은 발전된 기술들이 적극 도입되었다.
현재 프로젝트의 구조를 도식화하면 아래와 같다.
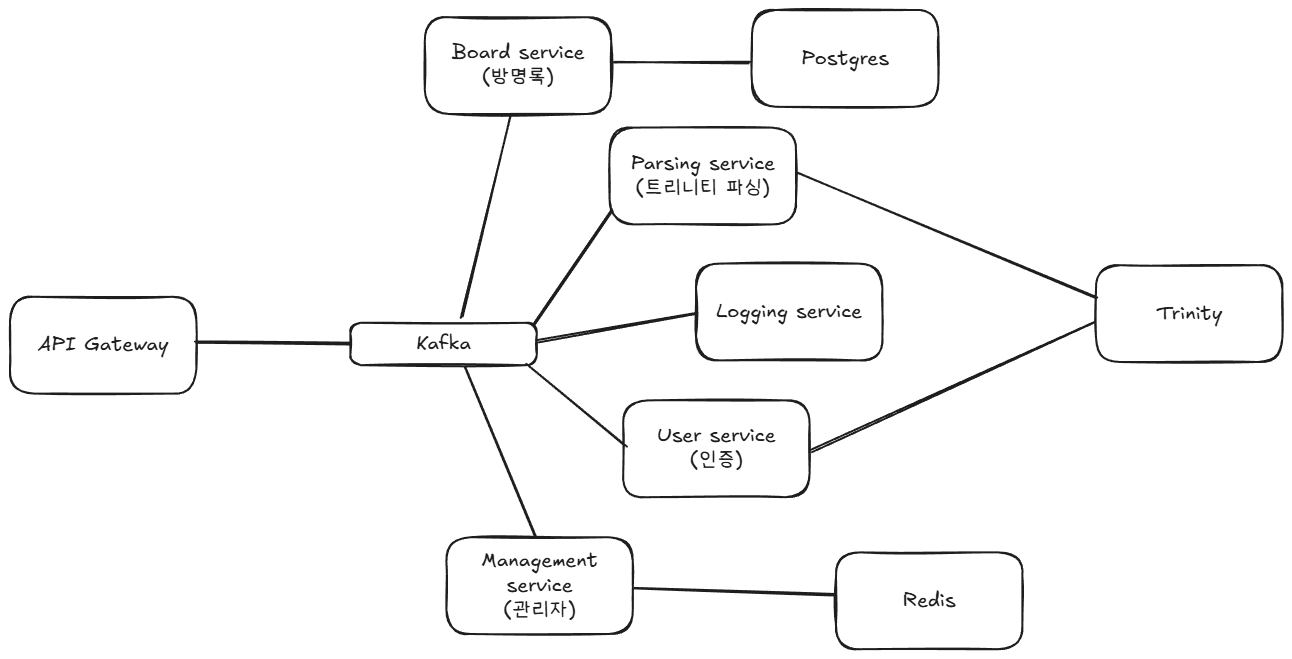
비교적 단순한 형태이다.
각 서비스들은 서로 통신을 위해서 절대 직접적으로 연결되지 않고 무조건 kafka를 거친다.
좀 더 고도화하자면, K8S 같은걸 도입하고, Api gateway를 여러 개로 늘려야 될 수 있을 것이다.
하지만, 그건 진짜 트래픽이 큰 실 서비스가 되었을 때의 얘기이다. 지금은 배보다 배꼽이 더 큰 상황이 될 수 있다.
아, MSA를 구현할 때 예전부터 궁금했던 건데 공통으로 사용되는 DTO 같은 것들은 각 서비스마다 파일을 만들어서 정의되어야 하는 것이 아니라 공통 Lib로 다뤄질 필요가 있는 것이었다.
이를 감안해서 지금 프로젝트에서 JWT 토큰 검증과 같은 Auth Guard 로직이나 공통으로 사용되는 Request or Response DTO들은 공통 Lib에 두고 배포 시점에 각 서비스 내로 이동시켜준다.
4. 마무리
이번 리뉴얼에서는 실무에서 잠깐이나마 쌓은 지식들이 참 많이 도움이 되었다.
백엔드를 많이 엿봤고, 프론트엔드는 열심히 알아가고 있는 중이다.
AI Agent들이 성능이 엄청 좋아짐에 따라서 여러분들도 마음껏 무언가를 만들어낼 수 있다.
의미있는 것을 만들어 내기 위해서 다들 계속 도전할 수 있었으면 좋겠다.
'개발' 카테고리의 다른 글
| 클라이언트에서의 캐싱 구현 과정 (코드 X) (3) | 2026.02.09 |
|---|---|
| Nginx에서 하나의 Conf로 BE와 FE에 대한 경로 기반 라우팅 (리버스 프록시) 설정 (0) | 2026.01.12 |
| [Spring] BE에서 로깅이 하고 싶다면? (4) | 2025.11.16 |
| [Gerrit, Jenkins] Gerrit과 Jenkins 연동 (1) | 2025.10.19 |
| 리액트 (FE)를 Spring (BE)에 통합해 배포하기 (2) | 2025.10.09 |
